訓練模型的時候就像是做了一次次的實驗,如果沒有好好做每次訓練的實驗記錄,
當我們發現優秀的模型,想要再進一步重現與改進,將會非常困擾,因為我們已經再無數的實驗海裡迷失自我。
今天把 「記錄實驗 → 註冊模型」 走完一遍。你會看懂 MLflow 四大元件:
目標:用最簡單的「人氣榜推薦」做成 PyFunc 模型,記錄 → 註冊 → 載入推論。
[Notebook] → log_param / log_metric / log_model
↓ │
[Tracking DB: Postgres] [Artifact: ./workspace/mlruns]
↓ │
[Model Registry (Versions & Stages)]
在 python-dev 容器的 JupyterLab 開一支 notebooks/day2_mlflow_basics.ipynb:
import os, mlflow
# 設定 MLflow Tracking Server 的位置
# 1. 先嘗試讀取環境變數 MLFLOW_TRACKING_URI
# 2. 如果沒有設定,就預設連到 http://mlflow:5000
mlflow.set_tracking_uri(os.getenv("MLFLOW_TRACKING_URI", "http://mlflow:5000"))
# 指定實驗名稱為 "anime-recsys"
# - 如果這個實驗不存在,MLflow 會自動建立一個新的。已經存在,就直接切換到那個實驗
exp = mlflow.set_experiment("anime-recsys")
# 印出目前使用的 Tracking URI 與實驗 ID
print("Tracking URI:", mlflow.get_tracking_uri(), "ExpID:", exp.experiment_id)
import time
from pathlib import Path
with mlflow.start_run(run_name="day2-sanity"):
mlflow.log_params({"algo":"popular","top_k":10})
for step in range(1,6):
mlflow.log_metric("precision_at_k", 0.20+step*0.02, step=step)
time.sleep(0.05)
Path("artifacts").mkdir(exist_ok=True)
Path("artifacts/README.txt").write_text("Day2 sanity run for MLflow.")
mlflow.log_artifact("artifacts/README.txt")
讓我們來看一下:
mlflow.log_metric("precision_at_k", 0.20+step*0.02, step=step)
這行的作用是 在 MLflow 裡記錄一個 metric(指標),名叫"precision_at_k"
在推薦系統裡常用 Precision@K:衡量「推薦前 K 個結果裡,有多少比例是使用者真的喜歡的」。
這裡只是模擬數值,不是真正計算。
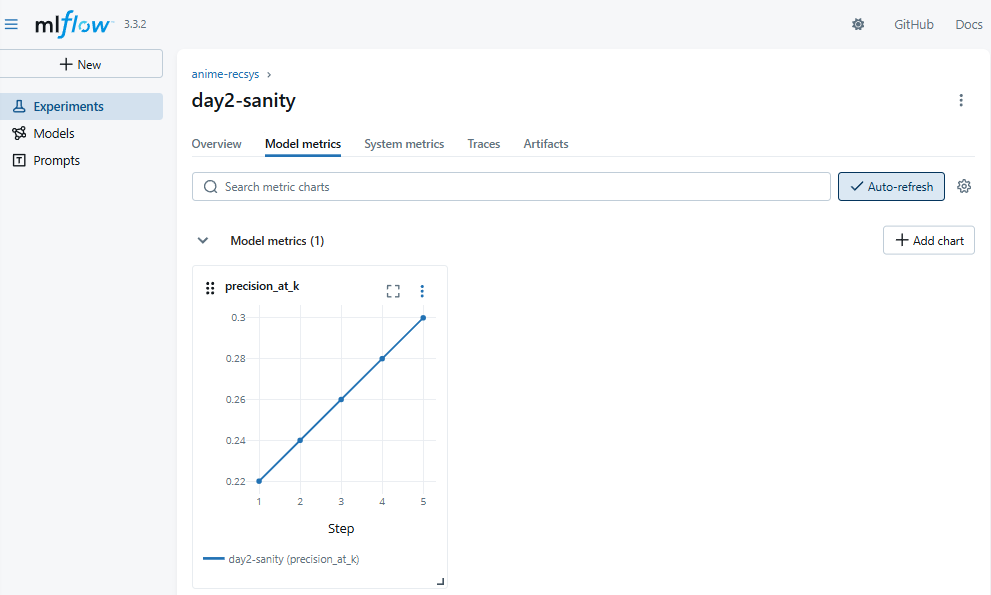
step 從 1 到 5,所以數值依序是:0.22, 0.24, 0.26, 0.28, 0.30。
這樣可以模擬「模型隨著迭代,Precision 慢慢提高」。
在 MLflow UI 上會畫折線圖,X 軸是 step,Y 軸是 precision_at_k。
所以會看到一條逐步上升的曲線。
打開 MLflow UI(
http://localhost:5000)看見 run 與 artifact。
用「最受歡迎清單」當作模型,輸入使用者喜歡的動畫,排除已看過後回傳 Top-K。
import pandas as pd
import mlflow
import mlflow.pyfunc as pyfunc
from pathlib import Path
from mlflow.models.signature import infer_signature
POPULAR = ["Naruto","One Piece","Bleach","Death Note","Your Name","Attack on Titan"]
# 準備 artifact
Path("artifacts").mkdir(exist_ok=True)
Path("artifacts/popular.txt").write_text("\n".join(POPULAR), encoding="utf-8")
class PopularRecs(pyfunc.PythonModel):
def load_context(self, context):
"""
當 MLflow 載入模型時,會先執行這個方法。
這裡的任務是把訓練時存好的 artifact (人氣榜清單) 載入到記憶體。
context.artifacts 是 MLflow 在載入模型時,幫你存放的檔案清單
"""
with open(context.artifacts["popular_list"], encoding="utf-8") as f:
# 讀取每一行,去除換行符號與空白行
self.popular_list = [line.strip() for line in f if line.strip()]
def predict(self, context, model_input: pd.DataFrame):
"""
推論邏輯:
1. 取得使用者已看過的動畫 (liked_titles)
2. 把多個清單展平成一個大清單
3. 轉成集合,避免重複
4. 從人氣榜裡排除已看過的動畫
5. 回傳前 k 個推薦結果
"""
# 假設 liked_titles = [["Naruto", "Bleach"], ["One Piece"]]
liked_titles = model_input["liked_titles"].tolist()
# 用 list comprehension 展平:["Naruto", "Bleach", "One Piece"]
all_watched = []
for sublist in liked_titles:
all_watched.extend(sublist) # 把每個小清單接到大清單
watched_set = set(all_watched)
# 轉成集合 (去重)
watched_set = set(all_watched)
# 從輸入資料中取得 k,如果沒給就用 5
k = model_input.get("k", pd.Series([5])).iloc[0]
# 推薦邏輯:從人氣榜裡排除已看過的動畫,取前 k 個
recommendations = [
title for title in self.popular_list if title not in watched_set
][:int(k)]
# 回傳 DataFrame,保持與 MLflow 定義一致
return pd.DataFrame({"recommendations": [recommendations]})
input_example = pd.DataFrame({"liked_titles":[["Naruto","Bleach"]], "k":[5]})
output_example = pd.DataFrame({"recommendations":[["One Piece","Death Note","Your Name","Attack on Titan"]]})
signature = infer_signature(input_example, output_example)
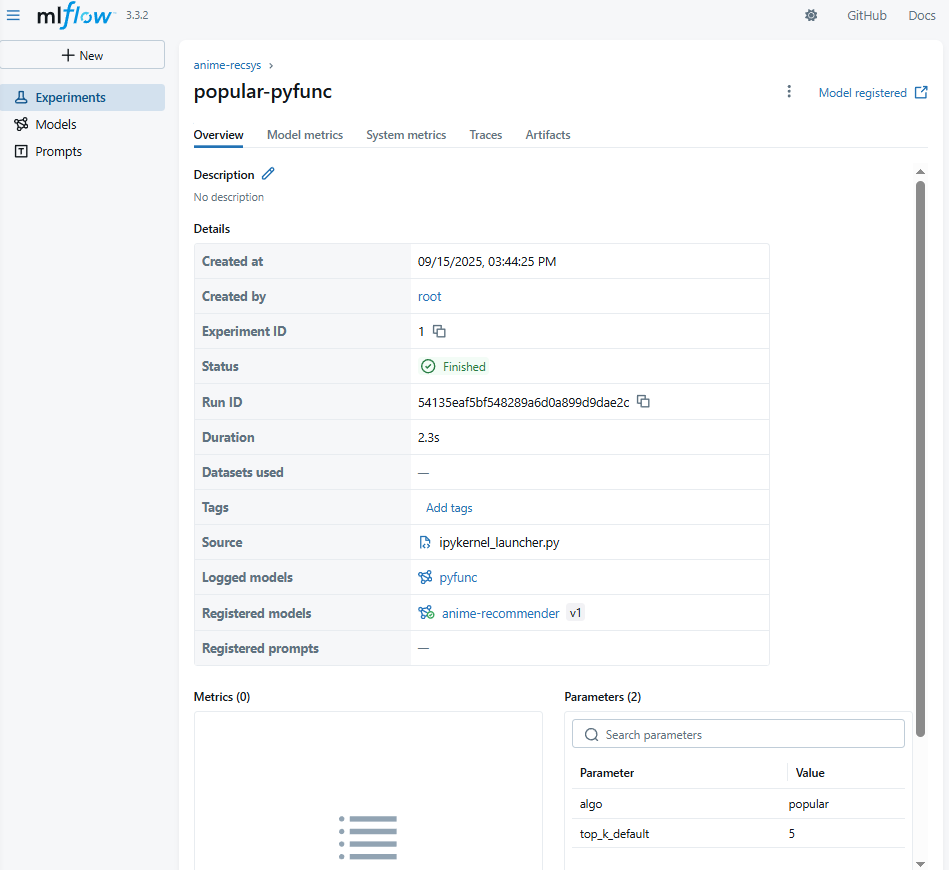
with mlflow.start_run(run_name="popular-pyfunc") as run:
mlflow.log_params({"algo":"popular","top_k_default":5})
mlflow.pyfunc.log_model(
artifact_path="model",
python_model=PopularRecs(),
artifacts={"popular_list":"artifacts/popular.txt"},
input_example=input_example,
signature=signature
)
run_id = run.info.run_id
print("Run ID:", run_id)
TODO(留給你):把
POPULAR改為「從 Kaggle 評分計算的人氣榜」。等 Day 3 抓資料後補上。
from mlflow.tracking import MlflowClient
import mlflow
client = MlflowClient()
model_uri = f"runs:/{run_id}/model"
name = "anime-recommender"
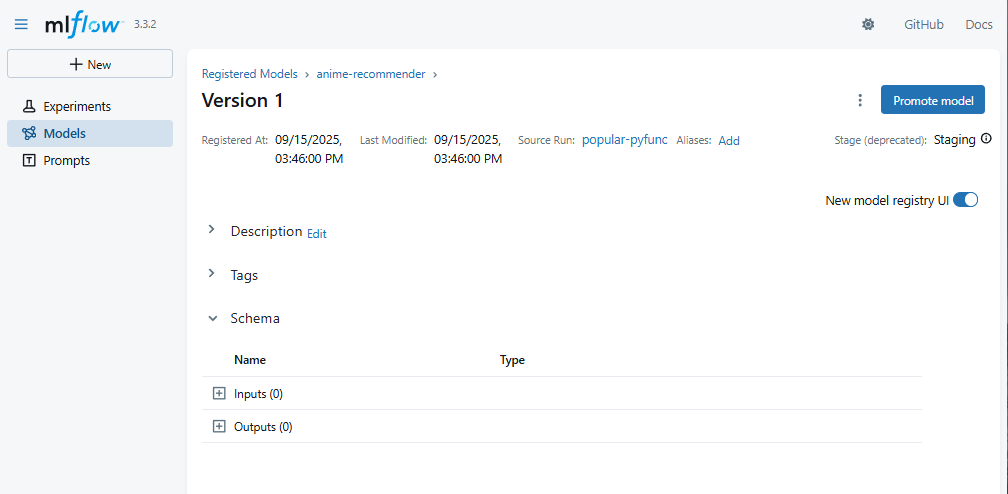
registered = mlflow.register_model(model_uri=model_uri, name=name)
client.transition_model_version_stage(
name=name, version=registered.version, stage="Staging", archive_existing_versions=False
)
print(f"Registered {name} v{registered.version} → Staging")
在 MLflow UI 的 Models 分頁可看到版本號與階段。
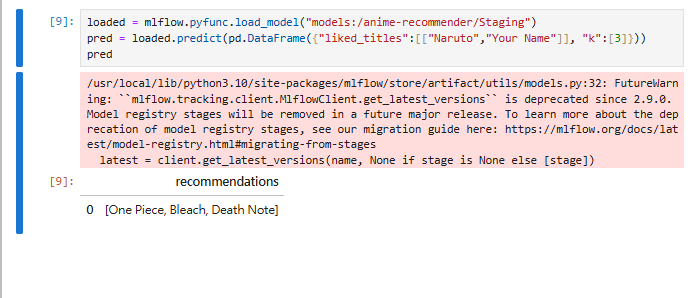
loaded = mlflow.pyfunc.load_model("models:/anime-recommender/Staging")
pred = loaded.predict(pd.DataFrame({"liked_titles":[["Naruto","Your Name"]], "k":[3]}))
pred
明天(Day 3)開始:從 Kaggle 自動抓動畫資料,把「人氣榜」真的算出來,並回填到今天的 TODO!


 iThome鐵人賽
iThome鐵人賽